eSenseを使うに当たって、自分の勉強も兼ねて、簡単なHuman Activity Recognition(他クラス分類)を自作した。(0)環境構築、(1)データ収集、(2)クリーニング、(3)特徴量抽出、(4)学習モデル選択・生成、(5)精度評価、(6)パラメータチューニングの手順を一通り試したので、その流れをメモしておく。機械学習の専門家では無いので、間違いがあったら教えて欲しい&もっと便利なテクニックがあったら教えて欲しいです。
0. 環境構築
今回の目的は、加速度と角速度データから「歩行・走行・階段・静止」などの行動を教師あり学習を用いて分類することです。全体的な流れとしては、まずはeSense+iOSアプリを使って加速度・角速度データをCSVフォーマットで保存する。保存したデータをPythonのpandasを使って読み込み、numpyを使って特徴量抽出(平均・分散・最大・最小)する。さらに、scikit-learnを使って学習モデルを作成し、まずはクロスバリデーションを使って精度を評価する。最後にパラメータチューニングに向けて、各特徴量の重要度を確認する。
1. データ収集
eSenseを使ってデータ収集。今回は加速度・角速度を50Hzでセンシングし、CSV形式で保存。
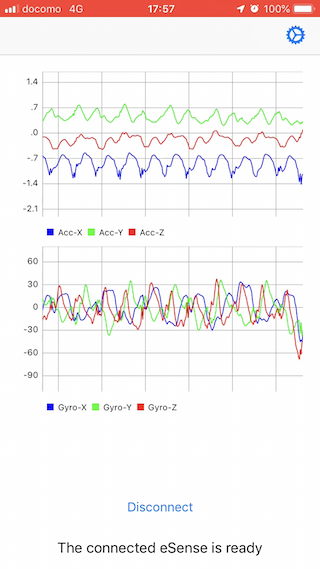

保存されたCSVファイルは、「CSV File Control」からAirDrop等で任意のデバイスに書き出すことができる。フォーマットは以下の通り。ラベル列に保存される文字列は、Labelから変更できる。
timestamp, device, timestamp, accx, accy, accz, gyrox, gyroy, gyroz, label
2. クリーニング
eSenseでは、ローパスフィルタをかけた状態でセンシングできるので、今回はローパスフィルタの適用は行わない。
まずはCSVデータを読み込み。
import pandas as pd
df = pd.read_csv("./esense2.csv", header=0, dtype = {'timestamp':'float','accx':'float','accy':'float','accz':'float','gyrox':'float','gyroy':'float','gyroz':'float', 'label':'str', 'device':'str'})
NAを削除する
df.dropna(inplace=True)
合計加速度を計算し、新しい列を追加する
df['accc'] = np.sqrt(df['accx']**2 + df['accy']**2 + df['accz']**2)
3. 特徴量抽出
加速度、角速度から特徴量を抽出(平均・分散・最大・最小・周波数特性)する。今回は、50Hzでセンシングしているので、1秒毎の動作を判定するには、64サンプルをひとまとめにして特徴量を抽出する。2の倍数にしているのは、FFTを行う際に2の倍数にする必要があるため。
DataFrameのunique()メソッドを使えば、label列に保存されてる、ユニークなラベル一覧を取得できる。df[df['label']=='TARGET_LABEL']を使えば指定したラベルに一致する行をまとめて取得できる。numpy型に変換する為には、一度list形式にする必要がある為、.valuesを使って、list形式でデータを取り出し、numpy形式に変換する。最終的には、numpyのreshape()メソッドを使ってデータを分割し、それぞれの平均値や分散を取得する。その際、全体数に合わない「配列形状」を指定すると、エラーが出るので、get_best_size()メソッドを使って事前に最適な配列数を取得しておく。FFTも行い、最も大きい周波数とその振幅を保存する。
import numpy as np
from numpy.fft import fftn
labels = df['label'].unique()
headers = ['accx','accy','accz','gyrox','gyroy','gyroz','accc']
batch_size = 64
def get_best_size(v, batch_size):
still = True
for best_size in reversed(range(0,v.size)):
if best_size%batch_size == 0:
return best_size
data = []
target = []
for label in labels:
v = np.array(df[df['label']==label][headers].values)
v = v[0:get_best_size(v.T[0], batch_size)]
features = []
for i, header in enumerate(headers):
sensor_data = v.T[i].reshape( (int(v.T[i].size/batch_size),batch_size) )
features.append(sensor_data.mean(axis=1).tolist())
features.append(sensor_data.max(axis=1).tolist())
features.append(sensor_data.min(axis=1).tolist())
features.append(sensor_data.std(axis=1).tolist())
features.append(sensor_data.var(axis=1).tolist())
F = np.fft.fft(sensor_data)
F_abs = np.abs(F) / batch_size * 2.
F_abs.T[0] = F_abs.T[0] / 2.
F_data = (F_abs.T[:int(sensor_data[0].size/2)+1]).T
features.append(F_data.argmax(axis=1).tolist())
features.append(F_data.max(axis=1).tolist())
if i == 0:
for lll in list(range(0, sensor_data.max(axis=1).size) ):
target.append(label)
data.extend(np.array(features).T.tolist())
4. 学習モデル生成
scikit-learnでは、様々な学習モデルをサポートしているので、簡単にモデルを切り替えることができ、生成モデルをiOSやAndroidに移植もできる。今回は、Multi-class SVM, KNeighborsClassifier, LogisticRegression, Random Forest を試してみた。
まずは先程作成したデータセットを「学習データ」と「テストデータ」に分割する。sklearnのtrain-test_split()メソッドが便利。使い方は簡単で、各学習モデルを初期化し、fit()メソッドを使って学習モデルを生成。生成後にpredict()を使って判定を行う。
from sklearn.datasets import load_digits from sklearn.multiclass import OneVsRestClassifier from sklearn.svm import SVC from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.metrics import confusion_matrix from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import classification_report from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier train_x, test_x, train_y, test_y = train_test_split(data, target) ### KNeighborsClassifier # classifier = KNeighborsClassifier(n_neighbors = 3) ### LogisticRegression # classifer = LogisticRegression() ### GradientBoostingClassifier classifier = GradientBoostingClassifier() ### Random Forest # https://ohke.hateblo.jp/entry/2017/08/04/230000 # classifier = RandomForestClassifier(min_samples_leaf=3, random_state=0) ### Multi-class SVM # estimator = SVC(C=1, kernel='rbf', gamma=0.01) # classifier = OneVsRestClassifier(estimator) classifier.fit(train_x,train_y) pred_y = classifier.predict(test_x)
5. 精度評価
主要な精度評価は以下のコマンドを使って行うことができる。
- confusion_matrix
- accuracy_score
- precision_score
- recall_score
- f1_score
- classification_report
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
%matplotlib inline
# https://pycarnival.com/fit_predict_scikitlearn/
# https://pythondatascience.plavox.info/scikit-learn/%E5%88%86%E9%A1%9E%E7%B5%90%E6%9E%9C%E3%81%AE%E3%83%A2%E3%83%87%E3%83%AB%E8%A9%95%E4%BE%A1
cm = confusion_matrix(test_y, pred_y, labels=labels)
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # normalize
cm_labeled = pd.DataFrame(cm, columns=labels, index=labels)
# https://note.nkmk.me/python-seaborn-heatmap/
sns.heatmap(cm_labeled, annot=True, square=True, cmap='Blues_r') #
# 本来ポジティブに分類すべきアイテムをポジティブに分類し、本来ネガティブに分類すべきアイテムをネガティブに分類できた割合
print(accuracy_score(test_y, pred_y))
# ポジティブに分類されたアイテムのうち、実際にポジティブであったアイテムの割合
print(precision_score(test_y, pred_y, average='weighted'))
# 本来ポジティブに分類すべきアイテムを、正しくポジティブに分類できたアイテムの割合
print(recall_score(test_y, pred_y, average='weighted'))
# 精度 (Precision) と検出率 (Recall) をバランス
print(f1_score(test_y, pred_y, average='weighted'))
# 全部一度に評価
print(classification_report(test_y, pred_y))
# http://datalove.hatenadiary.jp/entry/how-to-resolve-f-score-ill-defined-error
# Error: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples
# 多クラス分類の算出方法については以下のリンクを参考にすると非常にわかりやすい
# https://www.haya-programming.com/entry/2018/03/14/112454#%E5%A4%9A%E3%82%AF%E3%83%A9%E3%82%B9%E5%88%86%E9%A1%9E%E7%B7%A8
# https://note.nkmk.me/python-sklearn-confusion-matrix-score/
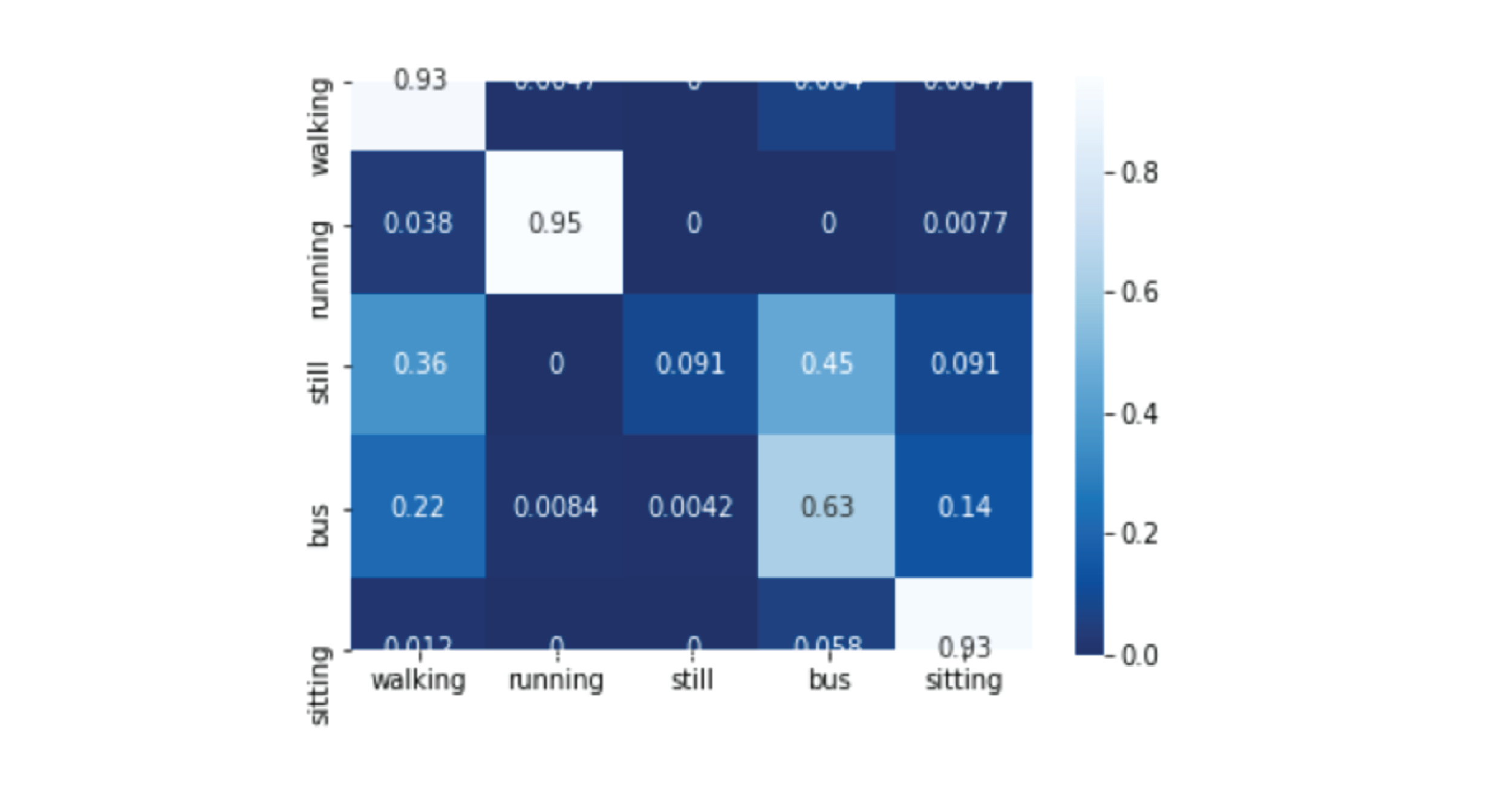
結果は以下のように表示される。学習データ量に偏りがあるので暫定ではあるが、この時点でも80-90パーセントぐらいの精度が出ている。
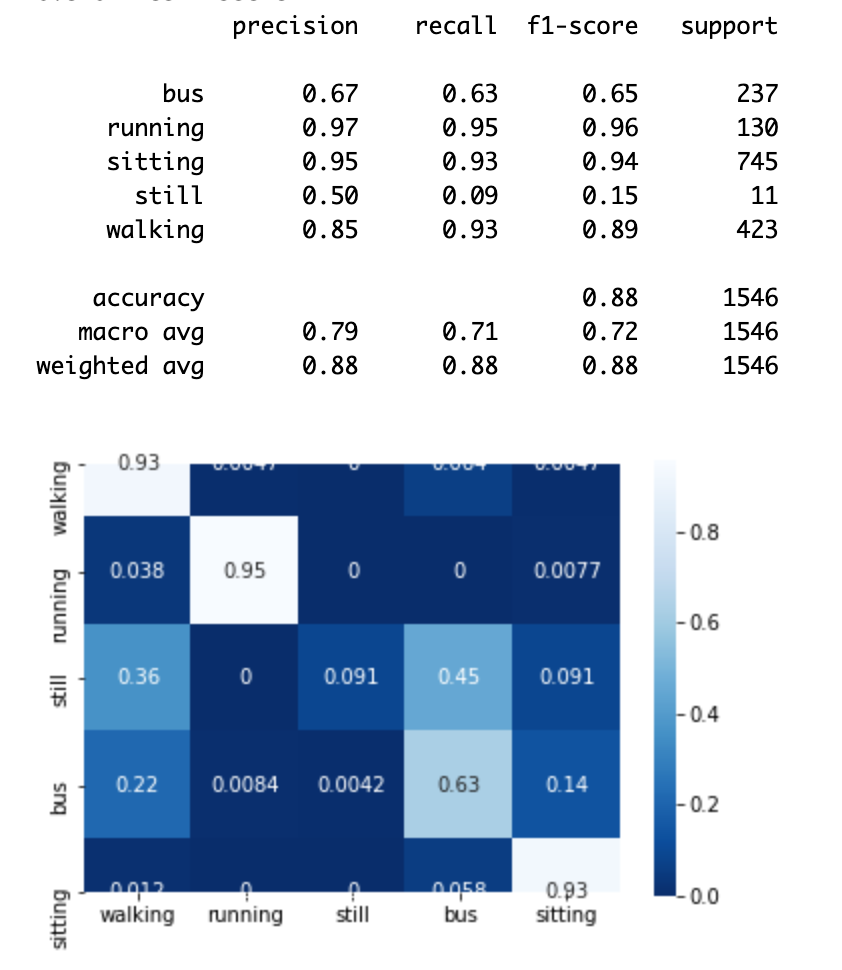
6. パラメータチューニング
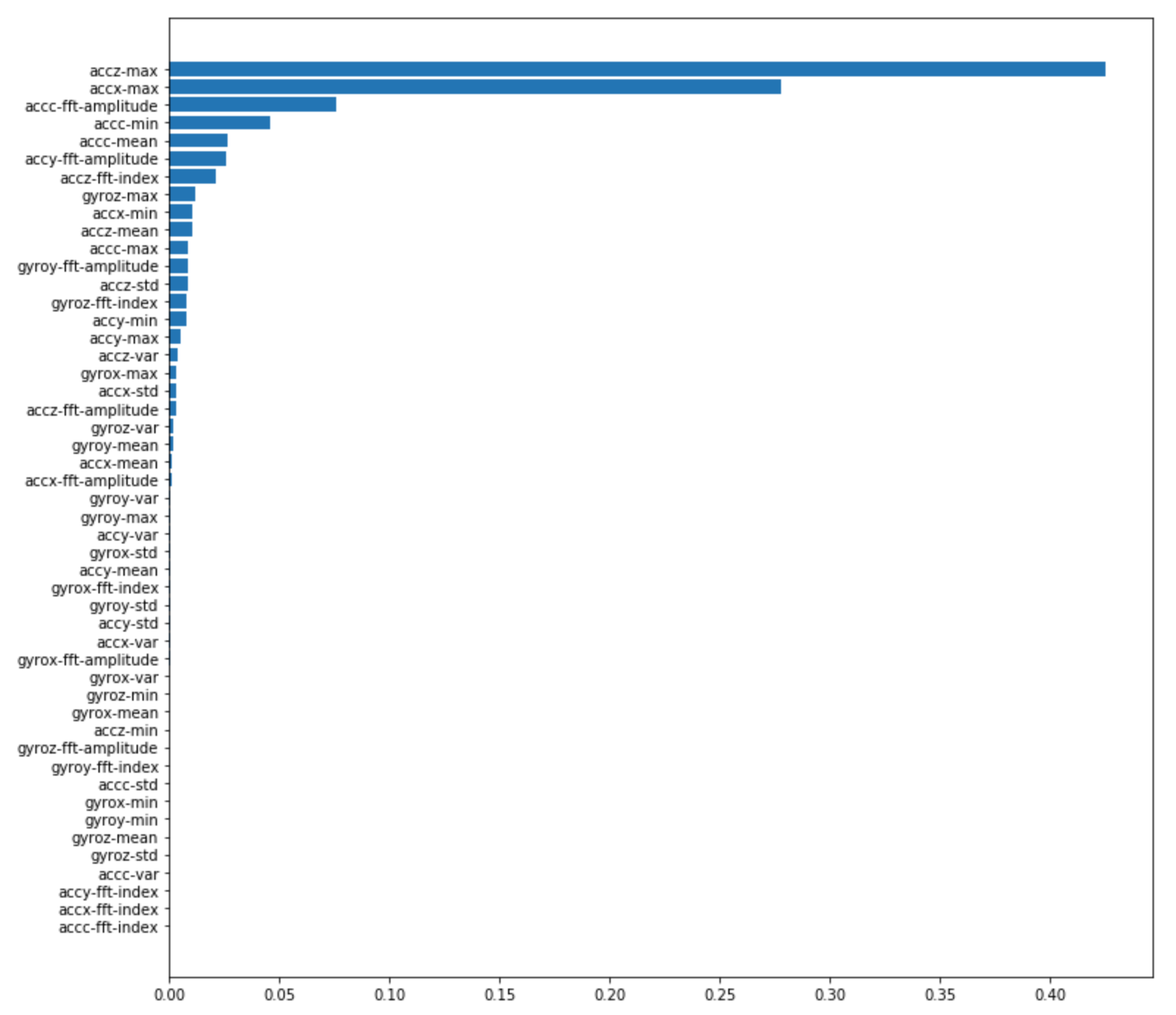
各特徴量の重要性は、feature_importancesを使ってリストアップすることができる。
columns = [] for x in headers: for y in ['mean','max','min','std','var']: columns.append(x+'-'+y) columns.append(x+'-fft-index') columns.append(x+'-fft-amplitude') values, names = zip(*sorted(zip(classifier.feature_importances_, columns))) plt.figure(figsize=(12,12)) plt.barh(range(len(names)), values, align='center') plt.yticks(range(len(names)), names)
加速度XZ軸の最大値、合成加速度の平均と最小値、合成加速度とY軸加速度の振幅、Z軸加速度の周波数が影響力の大きな周波数みたい。
最後に
非常に簡単なクラス分類モデルはあったが、データセットさえ準備できれば思っていたより簡単にscikit-learnを扱うことができた。次はしっかりデータセットを集めてモデルを作る、モバイルアプリへの統合、既存論文手法の再現などもできればと思います。